THOR Challenge
Navigate and find objects in a virtual environment

For the full release of AI2-THOR, please refer to this link.
In this challenge, the task is to navigate towards a set of objects in indoor scenes based only on visual input. AI2-THOR enables navigation in a set of near-photo-realistic indoor scenes, and we will use this framework for the challenge. The agents that the challenge participants provide receive visual input from THOR and should perform an action based on the visual input.
Competition Conclusion
A team from National Tsing Hua University (NTHU) has won the THOR challenge with their strong showing on the discrete navigation challenge.
The NTHU team will present their work in the Workshop on Visual Understanding Across Modalities @ CVPR 2:00-2:30 pm on 7/26. Everyone is encouraged to attend!
Discrete Navigation Leaderboard
| Rank | Entrant | Score |
|---|---|---|
| 1 | JamesChuang | 0.04248 |
| 2 | phunghx | 0.01651 |
| 3 | random | 0.00001 |
Test Data
The test data for the THOR challenge is now available. To use it, please download the test target definition file and the THOR build corresponding to your architecture linked here. Installation is unchanged from the instructions below, simply replace the THOR build where it appears.
wget https://s3-us-west-2.amazonaws.com/ai2-vision-robosims/builds/thor-challenge-targets-test.zip
wget https://s3-us-west-2.amazonaws.com/ai2-vision-robosims/builds/thor-201706291201-OSXIntel64.zip
wget https://s3-us-west-2.amazonaws.com/ai2-vision-robosims/builds/thor-201706291201-Linux64.zip
The instructions for running the robosims framework are also unchanged from those given below. You need only to replace the training targets file with thor-challenge-targets-test.zip and the THOR build given in unity_path with the appropriate OSX or Linux build linked here.
Tasks
The task is to navigate and find objects using a set of predefined actions. The agent is placed in a random location within the scene and provided a target image (e.g. image of an apple). The action set is (MoveAhead, MoveRight, MoveLeft, MoveBack, LookUp, LookDown, RotateRight, RotateLeft). The agent must not only navigate to the closest point possible to the object, but also be looking at the object. The release for the challenge includes 30 scenes (15 kitchens and 15 living rooms), where 20 scenes are training scenes, and 10 scenes are for validation. We will release the test scenes later.
| Target Image | Agent Start Position | Agent Target Position |
|---|---|---|
 |
 |
 |
Competition
The evaluation server is up and
running!
The evaluation server is being hosted by Codalab and can be found here.
A prize of $3,000 will be awarded separately to the highest scoring entrant of the discrete and continuous navigation subtasks.
To submit results, participants should:
- 1) Sign up for a Codalab account by clicking the Sign Up button on the competition page linked above.
- 2) Click on the Participate tab, agree to the terms and conditions, and click register.
- 3) If needed, navigate to the Participate tab and click on the Get Data side tab to download the train and dev sets.
- 4) Navigate to the Learn the Details tab and click on the Evaluation tab in the sidebar to read about the submission format required.
- 5) After your request is approved, navigate to the Participate tab and then click on the Submit/View Results tab in the sidebar.
- 6) Click the submit button and upload a results file.
- 7) After your submission is scored you will have a chance to review it before posting it to the leaderboard.
- 8) If you have questions, please ask them in the THOR competition forum (located under the Forum tab)
Dates
The tentative dates for the competition are:
| Test set is released | June 26th (tentative) |
| Final submission | July 15th (11:59PM GMT) |
| Winners announced | July 20th |
| Conference workshop | July 26th |
Installation
The framework for the challenge consists of three parts:
- THOR: Game engine that hosts the scenes (Linux/OSX)
- Robosims: Python framework which interacts with the game engine
- Targets: zip file containing a JSON targets file as well as target images
pip install https://s3-us-west-2.amazonaws.com/ai2-vision-robosims/builds/robosims-0.0.9-py2.py3-none-any.whl
wget https://s3-us-west-2.amazonaws.com/ai2-vision-robosims/builds/thor-201705011400-OSXIntel64.zip
wget https://s3-us-west-2.amazonaws.com/ai2-vision-robosims/builds/thor-challenge-targets.zip
unzip thor-challenge-targets.zip
unzip thor-201705011400-OSXIntel64.zip
To run on Linux you must have an X server running that has a GLX module enabled.
pip install https://s3-us-west-2.amazonaws.com/ai2-vision-robosims/builds/robosims-0.0.9-py2.py3-none-any.whl
wget https://s3-us-west-2.amazonaws.com/ai2-vision-robosims/builds/thor-201705011400-Linux64.zip
wget https://s3-us-west-2.amazonaws.com/ai2-vision-robosims/builds/thor-challenge-targets.zip
unzip thor-challenge-targets.zip
unzip thor-201705011400-Linux64.zip
Robosims Example - Training
#!/usr/bin/env python
import robosims
import json
env = robosims.controller.ChallengeController(
# Use unity_path=thor-201705011400-OSXIntel64.app/Contents/MacOS/thor-201705011400-OSXIntel64 for OSX
unity_path='projects/thor-201705011400-Linux64',
x_display="0.0" # this parameter is ignored on OSX, but you must set this to the appropriate display on Linux
)
env.start()
with open("thor-challenge-targets/targets-train.json") as f:
t = json.loads(f.read())
for target in t:
env.initialize_target(target)
# Possible actions are: MoveLeft, MoveRight, MoveAhead, MoveBack, LookUp, LookDown, RotateRight, RotateLeft
event = env.step(action=dict(action='MoveLeft'))
# path to the target image (e.g. apple, lettuce, keychain, etc.)
print(target['targetImage'])
# target_found() returns True/False if the target has been found
print(env.target_found())
# image of the current frame from the agent - numpy array of shape (300,300,3) in RGB order
image = event.frame
# True/False whether the last action was successful. Actions will fail if you attempt to move into a wall or
# LookUp/Down beyond the allowed range.
print(event.metadata['lastActionSuccess'])
{
"agentPositionIndex": 102, # corresponds to a point on the grid
"sceneIndex": 0, # which configuration for the scene (0-4)
"sceneName": "FloorPlan1", # the name of the scene
"startingHorizon": 330.0, # starting camera horizon (up,down) in degrees of the agent's camera
"startingRotation": 90.0, # global rotation of the agent
"targetAgentHorizon": 60.0, # where agent should be looking to see the target object
"targetAgentRotation": 180.0, # how the agent should be rotated to see the target object
"targetImage": "images/FloorPlan1/spoon.png", # path to image file that shows the target image
"targetObjectId": "Spoon|-01.73|+00.90|-00.95", # internal id of the target object
"targetPosition": {
"x": -0.6949999928474426,
"y": 0.9800000190734863,
"z": -1.7799999713897705
}, # final position to see the target object
"uuid": "a27cb81c-5f68-4f90-80e8-e01e49ab188d" # unique identifier for the task
},
Challenge Submission
The participants should submit a file that includes the taken actions. The code below shows how to use the API. While running against the validation scenes, the target_found() method will never return True. The agent must decide when it has reached the goal and cease performing actions. Once the agent has iterated through all the targets defined in the targets file, you can save the actions to a JSON file and submit to the CodaLab challenge.
#!/usr/bin/env python
import robosims
import json
env = robosims.controller.ChallengeController(
# Use for OSX
# unity_path='thor-201705011400-OSXIntel64.app/Contents/MacOS/thor-201705011400-OSXIntel64',
unity_path='projects/thor-201705011400-Linux64',
x_display="0.0",
record_actions=True
)
env.start()
with open("thor-challenge-targets/targets-val.json") as f:
t = json.loads(f.read())
for target in t:
env.initialize_target(target)
# navigate to the target
event = env.step(action=dict(action='MoveLeft'))
env.save_actions('submission-discrete.json')
Continuous vs Discrete Track
The challenge has two settings: (1) Discrete (2) Continuous. By default, the framework operates in discrete mode. This means that the agent navigates on a predefined grid. The agent is only able to look up and down in 30 degree increments and rotate in 90 degree increments. If an action is issued that pushes the agent into a wall, the agent will remain on the grid, but the lastActionSuccess value will be set to False. In continuous mode, the agent is free to rotate, look up/down and move in any amount. This allows the agent to collide with walls, move towards an object in fewer steps and rotate with greater precision.
# to enable continuous mode, pass the mode to the constructor
env = robosims.controller.ChallengeController(
# Use for OSX
# unity_path='thor-201705011400-OSXIntel64.app/Contents/MacOS/thor-201705011400-OSXIntel64',
unity_path='projects/thor-201705011400-Linux64',
x_display="0.0",
mode='continuous'
)
# All Move actions must include the moveMagnitude parameter
event = env.step(action=dict(action='MoveLeft', moveMagnitude=0.25))
# Rotate the agent to a specific rotation in global space
event = env.step(action=dict(action='Rotate', rotation=75.0))
# Move the horizon of the agent's camera (up/down)
event = env.step(action=dict(action='Look', horizon=35.0))
# Save actions for submission
env.save_actions('submission-continuous.json')
Evaluation
The evaluation score is calculated as the average of the optimum number of
actions (ot) over the predicted set of actions (pt) over all the tasks:
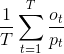
If the predicted set of actions do not place the agent in the correct location for a task, the score for that
task will be zero. The tasks include finding objects in different configurations of a scene from different
starting locations.
Organizers

Roozbeh Mottaghi
Allen Institute for AI

Eric Kolve
Allen Institute for AI

Daniel Gordon
University of Washington