Textbook Question Answering Challenge
Answer science questions from textual and visual source material

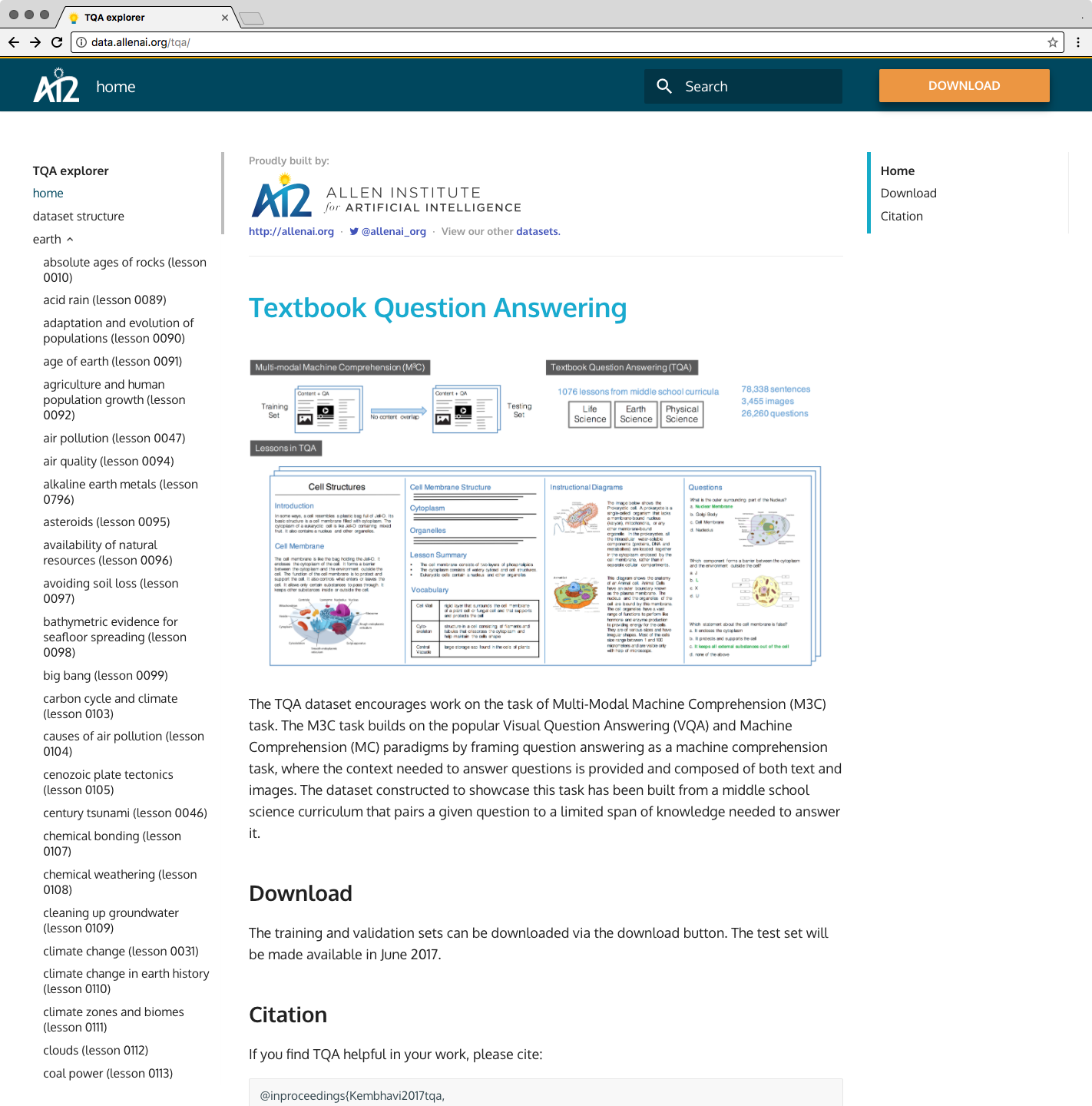
The TQA challenge encourages work on the task of Multi-Modal Machine Comprehension (M3C) task. The M3C task builds on the popular Visual Question Answering (VQA) and Machine Comprehension (MC) paradigms by framing question answering as a machine comprehension task, where the context needed to answer questions is provided and composed of both text and images. The dataset constructed to showcase this task has been built from a middle school science curriculum that pairs a given question to a limited span of knowledge needed to answer it. The phenomenon explained and tested on in middle school science can be fairly complex, and many questions require more than a simple look-up. Complex parsing of the source material and reasoning are often both required, as is connecting information provided jointly in text and diagrams. Recent work has shown that extensions of the state-of-the-art methods from MC and VQA perform poorly on this task. New ideas and techniques are needed to address the challenges introduced by this dataset.
Competition Conclusion
The TQA Challenge has a winner!
After an exceptionally close competition for 1st place on the text-question track, Monica Haurilet and Ziad Al-Halah from the Karlsruhe Institute of Technology emerged as winners of this half of 2017 Charades Challenge. Competition in the diagram-question track was nearly as close, but ultimately Yi Tay and Anthony Luu, Nanyang Technological University (Team NTU) emerged as the winners.
The challenge participants significantly improved state-of-the-art performance on TQA’s text-questions, while at the same time confirming the difficulty machine learning methods have answering questions posed with a diagram.
The teams will present their work in the Workshop on Visual Understanding Across Modalities @ CVPR 3:00-3:30 pm on 7/26, along with invited talks from Fei-Fei Li and Devi Parikh. Everyone is encouraged to attend!Text Question Leaderboard - Final
| Rank | Entrant | Accuracy |
|---|---|---|
| 1 | mlh | 0.4208 |
| 2 | beethoven | 0.4200 |
| 3 | tuanluu | 0.4100 |
| 4 | Daesik | 0.4021 |
| 5 | akshay107 | 0.3822 |
| 6 | freerailway | 0.3436 |
Diagram Question Leaderboard - Final
| Rank | Entrant | Accuracy |
|---|---|---|
| 1 | beethoven | 0.3175 |
| 2 | mlh | 0.3139 |
| 3 | tuanluu | 0.3050 |
| 4 | Daesik | 0.2588 |
| 5 | akshay107 | 0.2581 |
Tracks
The TQA dataset consists of two types of questions: Diagram Questions and Text Questions. These questions are distinguished by the modalities of a context needed to answer them.
Diagram Questions need an accompanying diagram to answer in addition to the
the text and diagrammatic content in the context.
Text Questions can be answered with only the textual portion of context.
The TQA challenge has 2 tracks, one for each of these question types:
Track 1- Text Questions Track
Track 2- Diagram Questions Track
Separate leader boards are maintained for performance on Diagram and Text Questions, and winners will be declared for both. Diagram and text questions are easily separated in the dataset, and details for doing so are given here.
Researchers are greatly encouraged to submit a model that works well on both types of questions.
Competition
The evaluation server is up and
running!
The evaluation server is being hosted by Codalab and can be found here.
A prize of $3,000 will be awarded separately to the highest scoring entrant of the diagram and text-only question answering subtasks.
To submit results, participants should:
- 1) Sign up for a Codalab account by clicking the Sign Up button on the competition page linked above.
- 2) Click on the Participate tab, agree to the terms and conditions, and click register.
- 3) If needed, navigate to the Participate tab and click on the Get Data side tab to download the train and dev sets.
- 4) Navigate to the Learn the Details tab and click on the Evaluation tab in the sidebar to read about the submission format required.
- 5) After your request is approved, navigate to the Participate tab and then click on the Submit/View Results tab in the sidebar.
- 6) Click the submit button and upload a results file.
- 7) After your submission is scored you will have a chance to review it before posting it to the leaderboard.
- 8) If you have questions, please ask them in the TQA competition forum (located under the Forum tab)
Dataset
The TextbookQuestionAnswering (TQA) dataset is drawn from middle school science curricula. It consists of 1,076 lessons from Life Science, Earth Science and Physical Science textbooks downloaded from www.ck12.org. Each lesson has a set of multiple choice questions that address concepts taught in that lesson. The number of choices varies from two to seven. TQA has a total of 26,260 questions including 12,567 having an accompanying diagram. The dataset is split into a training, validation and test set at lesson level. The training set consists of 666 lessons and 15,154 questions, the validation set consists of 200 lessons and 5,309 questions and the test set consists of 210 lessons and 5,797 questions. On occasions, multiple lessons have an overlap in the concepts they teach. Care has been taken to group these lessons before splitting the data, so as to minimize the concept overlap between data splits.
You can use this interactive tool to explore the dataset. With it, you'll be able to browse lessons organized by subject or search for words and phrases of interest. The complete questions and teaching material for every lesson in the training and validation sets are accessible, and it will provide an introduction to the dataset's content. Details of the organization and construction of the dataset are also found there.
Download
The training and validation sets can be downloaded here . The test set is now available to download here.
Dates
The tentative dates for the competition are:
| Test set is released | June 26th (tentative) |
| Final submission | July 15th (11:59PM GMT) |
| Winners announced | July 20th |
| Conference workshop | July 26th |
Paper
Are You Smarter Than A Sixth Grader?
Textbook Question Answering for Multimodal Machine Comprehension
@inproceedings{Kembhavi2017tqa,
title={Are You Smarter Than A Sixth Grader? Textbook Question Answering for Multimodal Machine Comprehension},
author={Aniruddha Kembhavi and Minjoon Seo and Dustin Schwenk and Jonghyun Choi and Ali Farhadi and Hannaneh Hajishirzi},
booktitle={Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2017}
}Organizers

Aniruddha Kembhavi
Allen Institute for AI

Dustin Schwenk
Allen Institute for AI